默认推荐
智能选择Auto(推荐)
TimechoAI 自研融合模型。系统会根据当前数据特征自动匹配最优预测策略,无需用户手动调参。
适用场景
适合绝大多数工业时序预测场景,推荐作为默认首选。
输入限制
推理请求大小上限为 20MB,最大输入长度 11520,最大输出长度 720,最多支持 50 个协变量。
在控制台创建一个新的会话,用于交互式预测与结果管理。
每次预测任务以「会话」为单位进行管理。点击页面左上角「新建会话」按钮,即可开始一次新的预测任务。
说明: 每个会话独立保存预测任务的数据、参数和结果。你可以随时在会话列表中切换查看历史预测记录。
打开 Timer 控制台并登录账号。
在预测工作区中新建会话,并选择合适的模型与参数。
上传数据或选择数据源,运行预测并查看输出结果。
新建会话后,首先需要为目标变量添加时序数据。系统提供三种数据输入方式,可根据实际情况选择其中一种。
适用场景: 快速验证预测效果,或无现成数据文件时。
绘制时尽量覆盖整个坐标区域,数据点越丰富,模型学习的规律越充分,预测效果越好。
适用场景: 已有数值数据,希望直接粘贴或手动录入。
时间戳,数值;也可仅输入不含时间戳的数值。数据格式示例:
2024-01-01 00:00:00,120
2024-01-01 01:00:00,135
2024-01-01 02:00:00,142每行格式为「时间,数值」,时间与数值之间用英文逗号分隔,时间建议使用等间隔格式(如每小时、每天)。
适用场景: 已有整理好的 CSV 或 TsFile 格式数据文件,是实际业务中最常用的方式。
支持的文件格式:
| 格式 | 说明 | 适用场景 |
|---|---|---|
| CSV | 逗号分隔的纯文本文件,通用性强 | Excel 导出、数据库导出等 |
| TsFile | 时序数据专用二进制格式,读写效率高 | IoTDB 等时序数据库导出 |
操作步骤:
页面底部提供三个示例文件可供下载:「纯数值」「带时间戳」「带协变量」,可直接上传体验完整流程。
协变量是影响目标变量的外部已知因素,例如温度、节假日、促销活动等。添加协变量可以帮助模型理解外部影响,从而提升预测精度。
根据协变量的未来数据是否可知,系统支持三种数据配置场景,精度依次提升:
| 场景 | 数据配置 | 说明 |
|---|---|---|
| 场景 1 | 仅目标变量 | 模型只使用历史目标值进行预测,适合没有外部影响因素的简单场景 |
| 场景 2 | 目标变量 + 协变量(无未来数据) | 协变量历史数据辅助建模,未来区间无协变量值,模型不使用未来外部信息 |
| 场景 3 | 目标变量 + 协变量(含未来数据) | 协变量历史和未来均已知(如节假日计划),模型精度最高 |
操作方式:
点击页面右上角「预测参数设置」按钮,打开参数面板,配置以下两个参数:
| 参数 | 含义 | 范围 / 默认值 | 使用建议 |
|---|---|---|---|
| 预测点数(steps) | 向未来预测的时间步数量 | 1–720,默认 10 | 根据实际需求填写 |
| 预测起始位置(start) | 从文件第几条数据开始作为预测起点 | 整数,默认为最后一条 | 留空即可,系统自动使用全部历史数据 |
若「预测起始位置」填入的值小于文件总行数,系统会用前 start 条数据进行预测,并与后续的 steps 条实际值进行对比,方便评估模型效果。
数据和参数配置完成后,点击右侧蓝色箭头按钮(→)提交预测任务。
页面底部提供三个内置示例,分别演示三种数据输入方式,可点击直接加载体验。
| 示例名称 | 数据输入方式 | 场景说明 |
|---|---|---|
| 预测销售额趋势 | 绘制曲线 | 通过鼠标手绘销售额历史曲线,体验快速预测流程 |
| 电力变压器的油温预测 | 输入数据 | 粘贴变压器油温时序数据,验证模型对工业数据的预测能力 |
| 预测冰淇淋销量 | 上传文件 | 上传带协变量(温度)的 CSV 文件,体验协变量联合预测 |
每个示例均已预填数据,点击示例名称即可一键加载,无需手动输入任何内容,适合初次体验时使用。
TimechoAI 自研融合模型。系统会根据当前数据特征自动匹配最优预测策略,无需用户手动调参。
适合绝大多数工业时序预测场景,推荐作为默认首选。
推理请求大小上限为 20MB,最大输入长度 11520,最大输出长度 720,最多支持 50 个协变量。
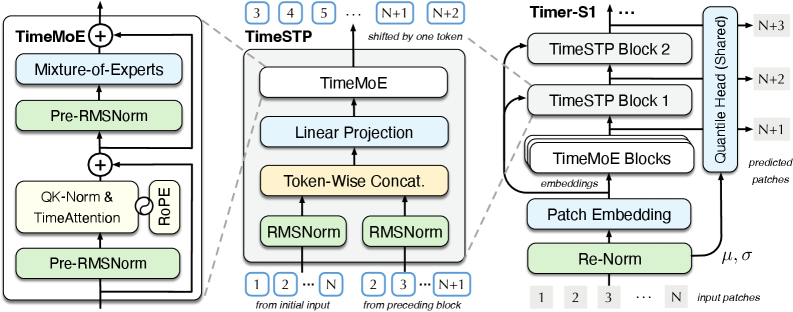
清华大学数据团队开源 Timer 时序大模型的 TimechoAI 优化版本,在预测精度和工业数据适配能力上表现更强。它可以给出不同置信水平下的预测结果,并按预测长度逐步生成未来趋势,更适合对准确性要求较高的业务。
适合对预测精度要求较高的场景。
推理请求大小上限为 20MB,最大输入长度 11520,最大输出长度 720,暂不支持协变量输入。
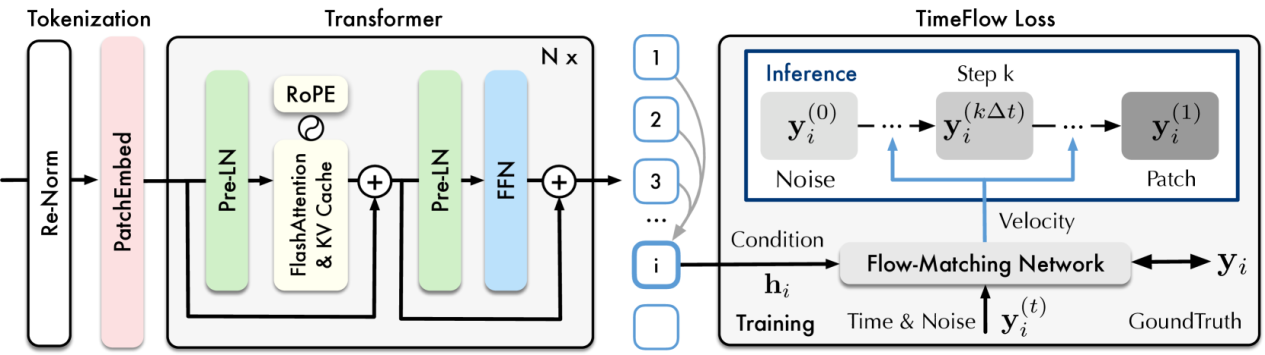
Timer 系列的稳定优化版本,具备较好的泛化能力与工业场景适配性。它会综合多条可能的未来走势形成预测结果,在数据形态多样、希望结果稳定的场景中表现更均衡。
适合对模型稳定性要求较高,或需与历史版本保持一致的场景。
推理请求大小上限为 20MB,最大输入长度 2880,最大输出长度 720,暂不支持协变量输入。
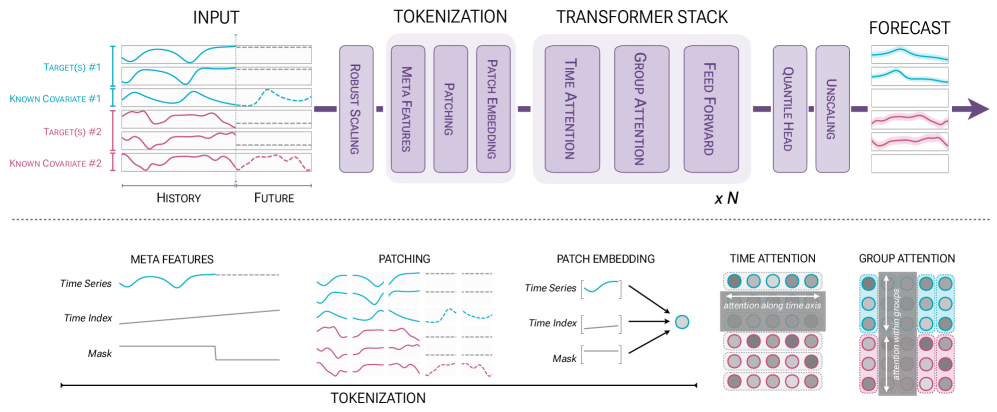
亚马逊开源时序预测大模型,具备较强的零样本预测能力,并支持多协变量输入。它可以同时参考目标序列、相关序列和外部变量,输出多步预测结果,适合需要结合业务影响因素一起判断未来趋势的任务。
适合用于效果对比评估,或探索性预测任务;也适合需要多协变量联合预测的场景。
推理请求大小上限为 20MB,最大输入长度 8192,最大输出长度 720,最多支持 50 个协变量。
经典统计预测模型,通过自动搜索最优参数组合拟合时序数据。
适合数据量较少、具有明显线性趋势或季节性规律的场景,也可作为基线参考模型。
推理请求大小上限为 20MB,最大输入长度 2880,最大输出长度 720,暂不支持协变量输入。
基于指数平滑的传统统计模型,专为含趋势性和季节性的时序数据设计,计算轻量、可解释性强。
适合周期规律明显的预测场景,或对计算资源有限制的环境。
推理请求大小上限为 20MB,最大输入长度 2880,最大输出长度 720,暂不支持协变量输入。
提示: 如不确定应选择哪个模型,建议使用 Auto,系统将自动为您的数据选择最优预测方案。如有更大规模的数据接入需求,可考虑私有化部署方案,欢迎联系我们了解详情。
Q:上传文件后,列角色自动识别错了怎么办?
在「标注列角色」面板中,手动点击每列的下拉菜单,选择正确的角色(时间 / 目标变量 / 协变量 / 忽略),然后点击「确认标注」即可。
Q:协变量不含未来数据,还能用协变量吗?
可以。将该列标注为「协变量」(不选「协变量(含未来数据)」),系统会仅使用该协变量的历史数据辅助预测。精度略低于提供协变量未来数据的情况,但仍优于不使用任何协变量。
Q:绘制曲线后能修改吗?
可以。点击「重置」清空画布后重新绘制,或切换到「输入数据」标签页手动修改具体数值。